Diseño y construcción de sistemas de trading (Parte I).
Pautas básicas para el diseño de estrategias de trading utilizando el filtrado de datos
El diseño de una estrategia de trading se puede abarcar desde diversos ángulos, desde la fuerza bruta, a través de redes neuronales o programación genética, como vimos en nuestro primer artículo o desde un enfoque “dirigido”, mediante un proceso de filtrado de los datos. Este va a ser el camino que desarrollaremos en las próximas líneas.
Nuestro cerebro es una máquina prodigiosa, capaz de sintetizar la inabarcable cantidad de información que le llega a través de los sentidos y procesarla de una manera eficaz y rápida con un único objetivo, nuestra supervivencia. Esta capacidad, tan valiosa en el día a día, puede suponer un verdadero hándicap a la hora de diseñar una estrategia de Trading. Esto es debido a que nuestro cerebro está optimizado para encontrar patrones hasta el punto de llegar a “inventarlos” en algunos casos. Una labor creativa de primer orden.
Debido a esta naturaleza, al presentar a la vista una serie temporal de cotizaciones, es sencillo vislumbrar figuras, líneas imaginarias, zonas de congestión, etc. En definitiva, “patrones” en la misma, los cuales podrían ser perfectamente fruto del azar. Esto lo realiza nuestro cerebro en cuestión de instantes. De ahí nacen las ideas, tal y como expusimos en nuestro artículo previo.
Resulta muy fácil coger un gráfico de cotizaciones y encontrar los puntos ideales de compra y venta de cualquier activo. El trader sabe que le será imposible “capturar” dichos puntos ideales de entrada y salida pero se conformaría con conseguir una parte sustancial de dichos recorridos. Sin embargo, el traslado de esa idea conceptual a un conjunto de reglas inequívocas y claras no es tan sencillo como cabría imaginar. Se establece un proceso de “deconstrucción” de la idea en sus elementos más sencillos con el objeto de poder ver el bosque y no sólo los árboles.
Debemos tener presente que en el trading sistemático, la interacción del humano con el mercado, se debe realizar actualmente con un intermediario necesario pero no humano, nuestra plataforma de trading. La complejidad, en muchos casos, no estriba en la comunicación con nuestro software (normalmente basta con aprender el lenguaje de programación de turno), sino en saber sintetizar la idea que queremos codificar.
Esta síntesis puede ser sencilla, tomemos como ejemplo que quisiéramos describir lo que es una mesa, sería sencillo descomponer la idea en sus elementos. Por otro lado podría ser extraordinariamente complicado, por ejemplo, describir lo que es “existir”. En el trading ocurre lo mismo, existen ideas que son extraordinariamente difíciles de codificar, pero no por la limitación del lenguaje de programación sino por la propia conceptualización (como puede ser la teoría de ondas de Elliot), es decir, por la falta de capacidad para descomponer la idea en elementos sencillos.
Y es que la idea necesita ser descompuesta en sus elementos lógicos uno a uno, ordenados en un flujo coherente y después codificados en un lenguaje de programación.
De esta forma el proceso sería el siguiente:

En este proceso hemos cogido una “base” que es una serie temporal cualquiera y que está constituida por la sucesión de los precios de cotización de determinado activo. Se han percibido ciertos patrones en ella por parte de nuestro cerebro, con ellos se ha generado una idea capaz de explotarlos. A continuación se descompone dicha idea en sus elementos y se ordena el flujo de los mismos. Por último trasladamos al lenguaje de programación de nuestra plataforma dicha Idea. Habremos conseguido comunicar a nuestro ordenador lo que queremos hacer.
La ulterior comunicación entre nuestra plataforma y el bróker ya no es un tema del que debamos preocuparnos aquí, supone una comunicación máquina-máquina. Veamos con detalle los aspectos de este proceso objeto de este artículo.
REGLAS DE LA OPERATIVA
Desde un punto de vista formal, las reglas no son otra cosa que la concreción lógica de las diferentes ideas de trading. Mientras que, desde un punto de vista estadístico, son restricciones condicionales que determinan los grados de libertad de una estrategia al ser aplicada sobre un conjunto de datos.
En el primer caso, pedimos diversidad y flexibilidad: esto es, que las reglas sean capaces de capturar una amplia gama de pautas o movimientos predefinidos en las formaciones de precios y que, al mismo tiempo, tengan cierta capacidad de adaptación a los cambios del mercado que se producen en plazos más largos; lo que nosotros denominamos marcoépocas.
En el segundo caso, nos movemos en la sutil dialéctica entre rendimiento óptimo y sobreoptimización: Las reglas de un sistema deben ser lo suficientemente sofisticadas como para identificar los movimientos de mayor probabilidad de beneficio en unos mercados en permanente proceso de cambio, pero no tanto como para encajar como un guante en los datos históricos, perdiendo toda capacidad predictiva.
Consideradas globalmente, las reglas que describen la lógica de un sistema pueden organizarse en las cuatro siguientes categorías:
a) Estadísticas: Ideadas para detectar patrones que se repiten con determinada frecuencia en las series históricas. Se trata de buscar una ventaja en términos probabilísticos (el edge) cuya persistencia pueda ser verificada en largos períodos de tiempo. En este tipo de reglas el elemento clave o “ratio diana” suele ser porcentaje medio esperado (PMO) de recorrido alcista/bajista cuando se produce alguno de los eventos o pautas que tratamos de capturar. Pongamos un ejemplo:
Programar un sistema que coloque órdenes en stop, en el máximo y mínimo de la sesión una vez transcurridas “x” barras desde la apertura.
Esta es la típica regla de entrada en sistemas ORB (Open Range Breakout). Con una formulación tan genérica posiblemente obtendremos resultados demasiado pobres en la mayoría de los mercados. Luego, para aumentar nuestro edge, o esperanza matemática, introducimos algunas otras reglas complementarias cuya única justificación es meramente estadística:
- Posicionarnos sólo cuando hayan transcurrido 20 minutos desde la apertura. ¿Por qué razón 20 y no 25, 45 o 50 min.? Sencillamente, porque hemos verificado que capturamos un PMO mayor en la barra de los 20 min. para tal mercado.
- Posicionarnos sólo si en las barras inmediatamente anteriores a la ruptura de la línea de máximos o mínimos aparece un NR3, NR4 o NR7 (en el argot del trader sistemático: Narrow Range o estrechamiento de rango de “x” barras). La determinación del valor predictivo de estas figuras, no es más que una cuestión estadística.
b) Técnicas: Todas aquellas reglas de posicionamiento que utilizan algún indicador para posicionarse o filtrar las señales. Constituyen el grupo más numeroso. De hecho hay sistemas construidos única y exclusivamente en torno a un indicador. Dado que todos los indicadores de volatilidad, de tendencia, de volumen, etc. utilizan parámetros, casi todas estas reglas requieren algún proceso de optimización para determinar los valores paramétricos idóneos para un determinado mercado y time frame. Ejemplos típicos de estas reglas:
- Comprar cuando el cierre de la última barra cruza por encima de la EMA (media exponencial) de 20 sesiones y el ADX (15) es mayor de 20. Incluso en una regla tan simple como ésta ya tenemos unos cuantos parámetros susceptibles de optimización: Número de barras de la EMA y del ADX y umbral de activación de este filtro. De todos es sabido el peligro de la sobre-optimización, pero este asunto será tratado en capítulo aparte.
- Salir de la posición si el parabólico se sitúa por debajo del mínimo barra y el valor neto de nuestra posición es mayor de 1.000 euros.
En este caso estamos combinando reglas técnicas con reglas basadas en el performance del sistema. Esto suele ser habitual en el diseño de subsistemas eficientes de salida.
c) Descriptivas: Aquellas que tratan de definir sucesos sistémicos que ocurren en determinadas sesiones del calendario del trader o en intradía. Algunas de estas reglas pueden responder a la categoría event driven, o posicionamiento dirigido por noticias. Algunos ejemplos:
- No operar el día del cambio de vencimiento de tal o cual producto derivado.
- Evitar los 20 minutos anteriores y posteriores a la apertura de los mercados USA.
- Detener la operativa en los minutos anteriores a la publicación de determinadas noticias macro que tienen un carácter regular, pero que disparan la volatilidad intradiaria.
d) Heurísticas: Este es el tipo de reglas más difícil de programar y, normalmente, requiere el empleo de algoritmos genéticos, lógica difusa y algunas técnicas de inteligencia artificial. Se trata de soluciones adaptativas que traten de ajustar automáticamente los parámetros, e incluso determinados elementos de la lógica, a la dinámica de los mercados.
Existen algunos dispositivos que generan automáticamente reglas derivadas y metareglas, incluso hay aplicaciones como Trading System Lab o Adaptrade Builder que cubren casi todas las etapas del proceso de producción de sistemas: elaboración de reglas, adaptación a uno varios mercados, testeo in-sample y out-sample, validación del constructo y codificación de la estrategia en el lenguaje de una determinada plataforma.
Desde un punto de vista funcional, podemos organizar las reglas en las cuatro siguientes categorías:
- Posicionamiento: Aquellas que describen la lógica de entrada al mercado. En algunos sistemas, particularmente del tipo intradiario, los filtros y el horario de activación, forman parte de la lógica. Normalmente la lógica de un sistema suele evaluarse por separado. Pero este es un tema largo al que ya dedicaremos otros artículos.
- Acompañamiento: El propósito de estas reglas es trabajarse la posición una vez que ya estamos en el mercado. Un ejemplo sencillo serán los filtros de volatilidad y direccionalidad que nos permiten incrementar o disminuir el tamaño de la posición para un rango específico de valores.
- Cierre: Subsistema de reglas con las que especificaremos las condiciones de salida de una posición: En esta categoría podemos incluir las distintas variedades de stop loss y target profits (porcentuales, dinámicos, trailing stops, break-even stops, ect.), así como las salidas por tiempo, por falta de actividad, incluso por protección de errores; por ejemplo, cuando se detectan problemas en la recepción de datos.
- De gestión monetaria: En esta categoría tenemos dos subgrupos; a) reglas basadas en el equity curve y en las estadísticas del sistema que toman como input la información sobre el track-record de operaciones (Ej. detener la operativa si la curva del beneficio cae por debajo de la media móvil de las últimas 50 operaciones), y b) reglas basadas en los distintos algoritmos de position sizing (optimal F, fixed fraction, fixed ratio, etc.)
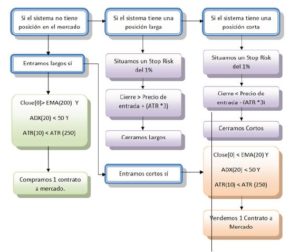
En el siguiente esquema podemos ver la interacción entre algunas de estas reglas (ver diagarama). En la próxima edición hablaremos de los componentes de la codificación.